

TL;DR: What the Codex 5.5 vs Opus 4.7 trend means for your AI agent stack
The Codex 5.5 vs Opus 4.7 spike is really about agents, not chat. Teams moved from "help me write a function" to an agent loop: read code, edit files, run tests, read logs, and repeat. That loop hits real constraints: monorepos, CI gates, and budgets that now demand repeatable results.
You can use TicNote Cloud to run GPT 5.5 vs. Opus 4.7 for free and decide which is the best, without a recurring argument. You're not picking "the best model." You're picking what fails less often on your harness, at a cost you can predict.
- Fast pick: use the faster, cheaper-in-loop option for interactive coding, tight feedback, and CI churn; use the more context-stable option for long, ambiguous, multi-file work where drift gets expensive.
- Real metric: compare by cost per successful completion = pass rate × retries × tool calls × tokens, not just list price per token.
- Operational win: publish one team routing checklist, then stop re-running "which model?" meetings.
Codex 5.5 vs Opus 4.7: what actually changed in 2026 (and why people care)
Why this is spiking now: agents turned model choice into ops risk
Agentic coding is a workflow, not a single answer. Each run can touch dozens of files, invoke tools, and trigger CI. So model choice now affects throughput and risk.
Here's what changed for many teams in 2026:
- Bigger contexts: more teams expect a model to reason across repos, not snippets.
- Harder gates: tests, linters, and security scans reduce "looks right" merges.
- Tighter spend: leaders ask for cost per successful completion, not vibes.
- Higher blast radius: subtle wrong edits increase incidents and on-call load.
If you're still treating this as dev ergonomics, you'll miss the cost center.
Common claims you'll see: efficiency, context, and reliability
Most claims fall into three buckets:
- Token efficiency: fewer tokens per task, shorter tool traces, and less rework.
- Benchmarks: higher "verified" scores and fewer hidden retries.
- Reliability: better instruction following and better tool use.
On context, people often compare 200k vs 128k tokens. In practice, "usable context" is smaller than the max. You still need room for prompts, tool output, and diffs. The question is simple: can it keep the right files in working memory long enough to finish the loop?
Reliability is also more concrete than it sounds. It means less drift mid-task, more clarifying questions before risky edits, and fewer changes that pass tests but break behavior.
What's still unclear: versions, harness, and benchmark inflation
This is where teams get fooled. You must label variables, or the comparison won't hold:
- Exact build and date (small releases can move results).
- API model vs product wrapper (system prompts and guardrails differ).
- Temperature, tool rules, and retry policy.
- Tool stack (shell, test runner, repo map, code search) and permissions.
Benchmark numbers also move when the harness changes. A different patch format, a new repo snapshot, or extra retries can inflate "wins." So this post won't declare an absolute winner. It gives you a decision framework and templates you can rerun, plus a safer mental model of AI agents vs assistants.
Methodology: how to compare frontier coding models without fooling yourself
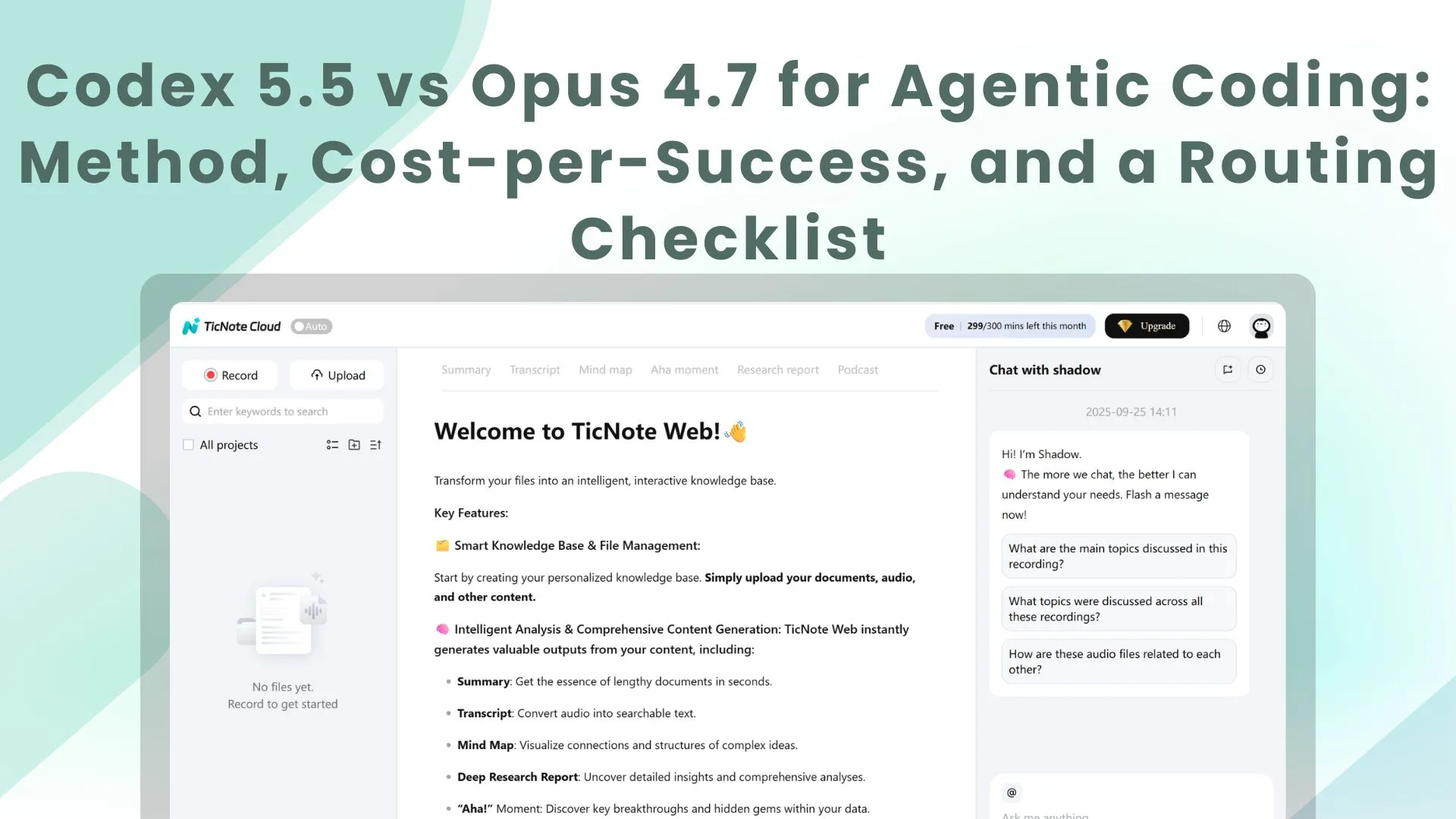
Most "model A vs model B" takes fail for one reason: the teams didn't hold the harness constant. If you're evaluating Codex 5.5 vs Opus 4.7 for agentic coding, treat it like a product change. Lock the loop, lock the tasks, and log everything. Then compare on cost per successful completion, not vibes.
Define your harness (tools, sandbox, tests, and stop rules)
Start by writing down the exact agent loop. This is the "how" behind every result. If it changes between runs, your numbers don't mean much.
At minimum, specify:
- Repo setup: commit hash, dependency install, env vars, and secrets policy
- Navigation tools: file search, ripgrep, symbol search, and how results are shown
- Edit tools: patch format, multi-file edits, and whether the agent can refactor freely
- Execution tools: test runner command, linter, formatter, and any build steps
- Verification: what must be true before the agent claims "done"
Now add stop rules. These prevent one model from "buying" a win with endless tries.
- Max wall-clock time (example: 12 minutes)
- Max tool calls (example: 40 total runs)
- Max retries (example: 3 full attempt loops)
- "Done" definition (example: tests pass + no linter errors + task acceptance note)
Finally, control variables. Keep them identical across models:
- Temperature / top-p
- System message and developer guidance
- Tool schemas and tool permissions
- Whether clarifying questions are allowed (and when)
Pick a task set that matches production (bugfix, refactor, tests)
Use a small suite you can rerun every time. Three to five tasks is enough for signal, if they're realistic.
A solid starter set:
- Bugfix task with a failing test that must turn green
- Refactor task with behavior locked (golden tests or snapshot tests)
- Test-writing task where coverage rises and failures catch the bug
Add one "ambiguous ticket." This checks a key agent skill: asking one good question instead of guessing. Score it explicitly: did it ask, did it assume, and did it break behavior?
Make tasks reproducible:
- Pin commit hashes
- Pin dependencies (lockfile)
- Fix the runtime image (same OS, same language version)
- Disable flaky network calls or mock them
Measure the right outputs (pass rate, retries, latency, tokens)
Pass rate alone hides the pain. For agentic coding, retries and tool runs are where time and cost explode.
Track these core metrics:
- pass@1 (success on first attempt)
- pass@k (success within k attempts)
- Mean retries per task
- Time-to-green (minutes to passing tests)
- Tool calls per task (tests, lint, search, build)
- Input/output tokens
- Diff size (lines changed) and files touched
Then normalize everything into one business metric:
- Cost per successful completion = (model tokens + tool costs + retries) ÷ successful tasks
Also log qualitative failure modes. They explain why a model "passed" but still hurt you:
- Drift (unasked scope creep)
- Partial fixes (tests pass but edge cases fail)
- Flaky wins (non-deterministic tests)
- "Looks right" output (compiles, but wrong behavior)
Record dates, settings, and sources (so results stay valid)
Frontier models change often. Your eval needs an "expiry date" unless you log a full header.
Use a copy/paste eval header like this:
- Date and timezone
- Model ID (exact) and provider
- Pricing snapshot used for math
- Context size used (and truncation rules)
- Cache/batch settings (on/off, assumptions)
- Harness version (tool schema + runner version)
- Temperature/top-p and system message hash
Store the artifacts, not just the summary:
- Full prompts and tool transcripts
- Git diffs and final branch state
- Test logs and linter output
- A short verdict note: why it failed or why it passed
Copyable internal doc skeleton (eval + routing rules)
Use this structure so decisions don't vanish in Slack:
- Goal: what you're optimizing (speed, accuracy, cost, autonomy)
- Harness: agent loop, tools, stop rules, fixed settings
- Task set: task IDs, commits, expected outputs
- Results table: pass@1, pass@k, retries, time-to-green, tool calls, tokens
- Cost per success: assumptions + sensitivity (retries, tool calls, caching)
- Failure modes: top 3 patterns with examples
- Routing rules: "Use X when…", "Use Y when…", "Fallback to…"
- Sign-off: owner, date, next re-eval trigger
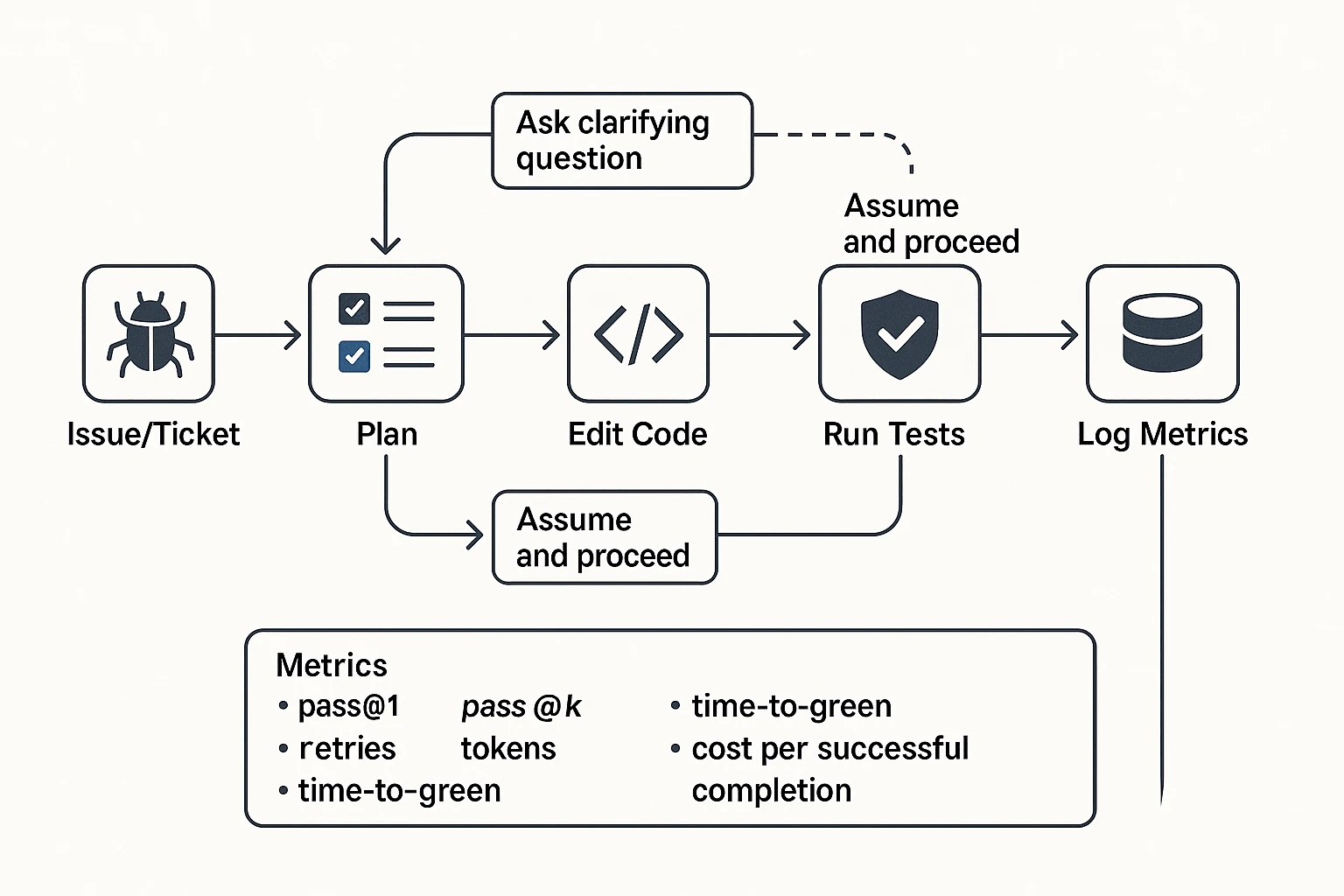
Side-by-side comparison table (benchmarks, context, speed, and ops constraints)
When people compare Codex 5.5 vs Opus 4.7 for agentic coding, the useful question isn't "which is smarter?" It's "which one stays stable in a tool loop, hits green faster, and costs less per success?" So below is a normalized view you can route on: context, latency shape, tool fit, and the ops knobs that change your bill.
Here's the quick table teams can copy into an eval doc.
| Dimension | Codex 5.5 | Opus 4.7 | What it means in practice |
| Context window (what it can hold) | Large enough for most repos but still benefits from pruning | Often strong at "reading the room" in long prompts, but still needs curating | Don't rely on raw context size. Use repo maps, focused diffs, and short task plans. |
| Typical latency profile | Snappy for short turns; can slow on long tool-heavy runs | Can be slower per turn, but may reduce back-and-forth on complex reasoning | Measure wall-clock time-to-green, not just "seconds per response." |
| Tool-calling fit (edit/test/search loops) | Strong for tight IDE-style loops and frequent small patches | Strong for multi-step reasoning with fewer, larger tool steps | For agents, the best model is the one that doesn't thrash your tools. |
| Prompt caching (cost lever) | Good fit for interactive agents that reuse a stable system prompt + repo summary | Same use case: repeated runs with the same base context | Prompt caching saves money when the prefix stays the same across many turns. |
| Batch API (cost lever) | Best for offline evals, backfills, nightly "try-fix" jobs | Same use case: high-volume, non-interactive runs | Batch cuts cost when you can wait and you want throughput over instant feedback. |
| Ops knobs you actually tune | Temperature, max tool calls, stop rules, diff size limits | Same knobs, plus stricter "ask before risky change" gating | Small guardrails often beat model switching for reliability. |
| Best use in routing (default / escalate / verify) | Default for everyday fix-test loops and incremental PRs | Escalate for ambiguous tasks, cross-service refactors, or deep reasoning | Verify with tests + lint + a second pass (either model) on risky diffs. |
How to read SWE-bench-style numbers like an engineer
SWE-bench Verified is a useful proxy for "bugfix + tests": the model gets a failing issue and must land a patch that passes a verified test suite. That approximates a real workflow step: find root cause, edit code, run tests, and stop when it's green.
But it misses common repo reality:
- Domain context: private APIs, tribal knowledge, and "why we do it this way."
- Flaky CI: intermittent failures that trigger retries and false negatives.
- Multi-service changes: schema + client + deploy scripts in one change.
So translate benchmark success into harness metrics you can control:
- Time-to-green (minutes): from task start to passing checks.
- Retries (count): how often the agent needed "one more run."
- Diff risk (low/med/high): touched files, API surface, and migration impact.
Before you trust external numbers, calibrate with 2–3 tasks from your own repo. Aim for 30–60 minutes of work each. That's usually enough to expose tool-loop pain, context issues, and retry rates.
Failure modes to watch (and the simple mitigations)
- Drift (goal changes mid-run): You'll see the agent "wander" into refactors. Fix it with smaller steps, explicit checkpoints (run tests, then stop), and a diff-size cap.
- Subtle-wrong (tests pass, behavior is wrong): Add stronger assertions, property tests (invariants), and negative cases. Don't treat green as truth.
- Ambiguity (acts without asking): Enforce a question-first rule when confidence is low (missing requirements, unclear env, or risky migrations).
Mini case studies you can reproduce this week
- Bugfix, one failing test (mid-size service)
- Input: failing unit test + stack trace + repo map.
- Output: minimal patch + updated test if needed.
- Track: pass@1, retries to green, total tokens, and wall-clock time.
- Refactor across 5–10 files (lint + formatting gates)
- Input: "rename X to Y," update callers, keep API stable.
- Output: consistent rename + passing lint.
- Track: tool calls (format/lint/test), drift incidents (unrequested edits), and revert rate.
- Long-context legacy module analysis
- Input: 2–4 key files + recent incidents + known constraints.
- Output: design note + risk list + staged plan.
- Track: context usage (how much you had to prune), reset frequency (how often it forgot), and plan quality (steps map to real files).
Cost reality: how token efficiency, retries, and tool runs change the bill
Token price isn't the unit that matters. In agentic coding (like codex 5.5 vs opus 4.7), the unit that matters is cost per successful completion.
Here's a clean definition you can use:
Cost per successful completion = (avg input tokens × input price) + (avg output tokens × output price) + tool overhead, all divided by success rate.
Why divide by success rate? Because an agent that "almost" finishes still burns tokens, tool runs, and time. A 10–20% gap in first-pass success often beats small token price differences.
Why agent loops amplify cost (and why verbosity hurts)
Agent runs aren't one prompt and one answer. They're loops: plan → edit → run tests → read failures → patch → re-run. Each loop adds:
- Extra output tokens (plans, diffs, explanations, test logs)
- More tool calls (repo search, build, test, lint)
- More retries when the model misses a constraint
So a model that is 30% more verbose can be far more than 30% more expensive in practice. The loop multiplies it.
At the same time, verbosity can help when a human is reading. Long reasoning, risk notes, and clear diffs can cut review time.
A copy-paste calculator table (with sensitivity rows)
Use this table to estimate task cost. Fill in your own prices and measured averages.
| Input | What you measure | Example value |
| Avg input tokens | prompt + context stuffed | 18,000 |
| Avg output tokens | plan + diff + notes | 3,500 |
| Tool calls per attempt | tests, search, formatter | 6 |
| Tool cost per call | CI minutes, hosted tools | $0.002 |
| Success rate per attempt | pass without retry | 0.70 |
| Expected retries | extra attempts after fail | 0.4 |
| Cache hit rate | % of input cached | 0.50 |
| Batch discount | if you can wait | 0.20 |
Now compute in steps:
- Attempts per success = 1 / success_rate
- Effective input tokens = input_tokens × (1 − cache_hit_rate)
- Base cost per attempt = (effective_input_tokens × input_price) + (output_tokens × output_price) + (tool_calls × tool_cost)
- Cost per successful completion = base_cost_per_attempt × attempts_per_success × (1 − batch_discount)
Sensitivity checks (quick "what ifs"):
- +1 retry: add one full extra attempt. That often adds 40–100% to cost on hard tasks.
- Tool calls doubled: common when tests are flaky. Tool overhead can dominate cheap-token models.
- Context stuffing +50%: happens when you dump the whole repo. Input costs spike unless caching is strong.
- Cache hit rate 0% → 80%: huge swing for repo-scale work. If you reuse the same 50–200k token context across 50 tasks, caching can drop effective input cost by 5×.
- Batch 0% → 20–50%: if work can run overnight (backfills, large refactors), batch pricing can turn "too expensive" into "fine."
When verbosity is a feature vs a cost
Route on purpose:
- Use a verbose model for design reviews, security/risk checks, and stakeholder-ready notes. You want traceable thinking and clear trade-offs.
- Use a concise model for execution loops: small fixes, refactors with tests, and high-volume generation (unit tests, API clients). You want fewer tokens per loop.
A simple control that works: add a verbosity budget in your system prompt (for example, "max 120 words of commentary") and require structured outputs (diff first, then short bullet notes). It keeps autonomy cheap without losing correctness.
Inline workflow tip: create a "Model Evals" Project in TicNote Cloud and store the calculator inputs, run logs, and final numbers in one place. That way finance and engineering share the same assumptions, and you don't re-litigate costs every sprint.
Decision guide: when should your team choose Codex 5.5, Opus 4.7, or both?
Most teams win by routing, not picking a single "best" model. In the Codex 5.5 vs Opus 4.7 debate, Codex tends to pay off on fast, tool-heavy loops, while Opus tends to pay off on long-horizon work with messy requirements. The practical goal is simple: pick the cheapest model that can succeed, then verify.
Choose Codex 5.5 when speed and tight loops matter
Codex 5.5 is the best default for high-throughput engineering chores. Think: lots of small fixes, lots of tests, lots of tool calls such as lint, typecheck, and unit tests, plus short feedback cycles.
Best-fit scenarios:
- High-volume bugfixes and test writing
- Refactors with clear acceptance checks, such as tests, snapshots, or static rules
- Pair-programmer loops where you run tools every 1–3 minutes
Why it works: token efficiency and short turnaround matter in CI-like workloads. If your agent does 3–10 iterations per task, faster loops usually beat deeper prose.
Risk to plan for: it can ship confidently with a wrong assumption. Mitigate with verify gates: require tests to pass, run static analysis, and do a quick diff review before merge.
Choose Opus 4.7 when the task is ambiguous or the context is huge
Opus 4.7 fits long-context reasoning and unclear tickets. It's the better option when the hard part is figuring out what to do, not typing code.
Best-fit scenarios:
- Large codebase analysis and "what's going on here?" debugging
- Multi-service changes where state must be tracked across files
- Architecture decisions, migrations, and tickets with missing details
Why it works: it tends to ask clarifying questions and keep a stable plan across long threads. That's valuable for unknown unknowns, where a fast first draft is often the wrong draft.
Risk to plan for: verbosity and cost. Mitigate by forcing structured output, such as bullets, checklists, or patch plans, and setting a verbosity cap, for example: max 8 bullets per section.
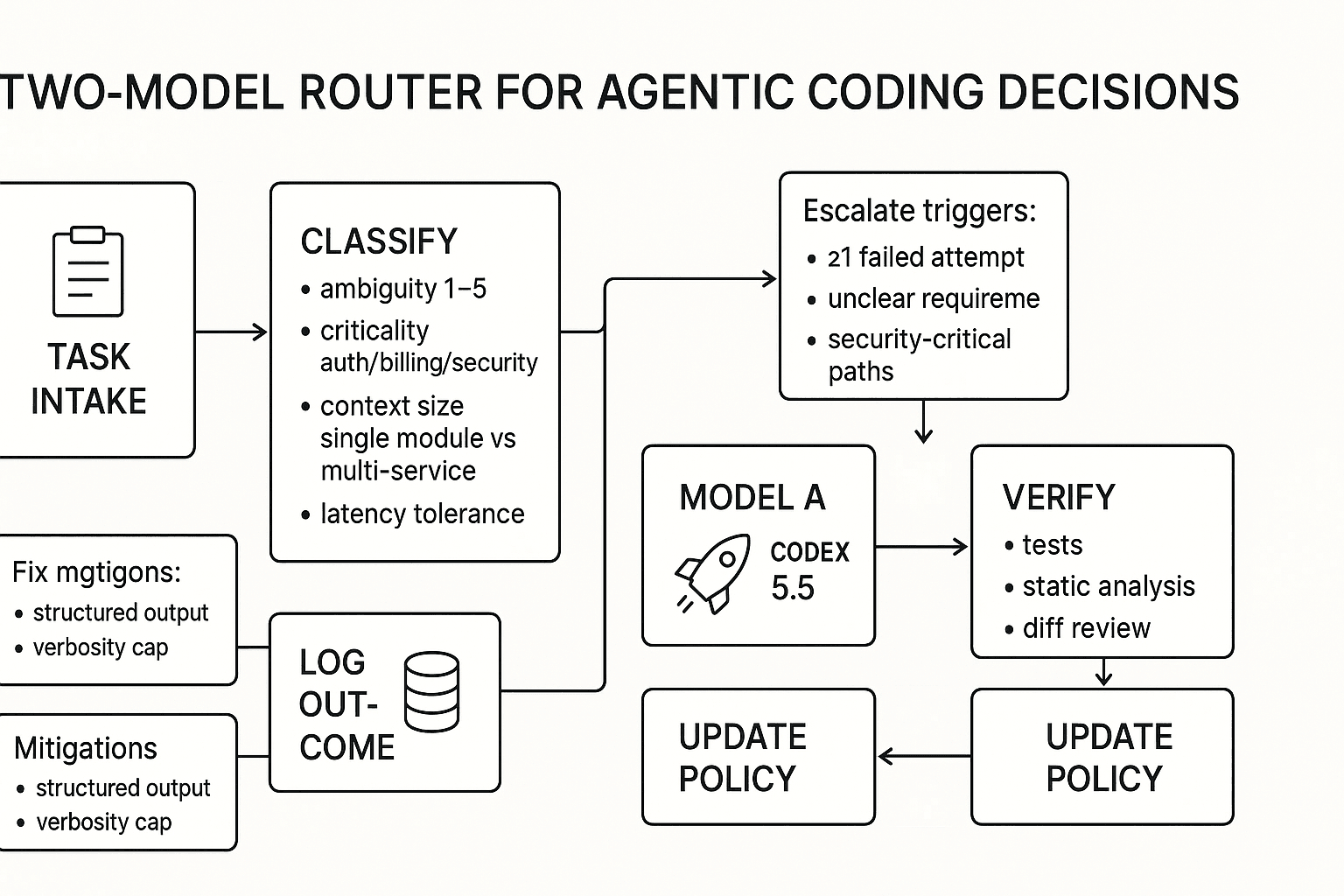
Run both with a simple router: escalate, fall back, verify
Copyable routing checklist:
- Task type: bugfix/test/refactor vs design/debug/architecture
- Repo context: small module vs multi-service and deep dependencies
- Ambiguity score from 1–5: are requirements crisp?
- Failure cost: can this break auth, billing, or data handling?
- Latency tolerance: do you need answers in under 60 seconds?
Escalate to Opus when any trigger hits:
- At least 1 failed attempt with Codex
- Requirements are unclear after one pass
- Touching auth, billing, or security-critical paths
Verify steps, always, for both models:
- Run unit and integration tests
- Run static analysis, including lint, typecheck, and SAST if you have it
- Do a minimal diff review and look for silent behavior changes
Mermaid flowchart for your docs:
\u0060\u0060\u0060mermaid flowchart TD A[Task intake] --> B{Classify} B --> C[Ambiguity score 1-5] B --> D[Criticality: auth/billing/security?] B --> E[Context size: single module or multi-service?]
C -->|1-2| F[Route: Codex 5.5] E -->|Single module| F
C -->|3-5| G[Route: Opus 4.7] E -->|Multi-service| G D -->|Yes| G
F --> H[Run tools + tests] G --> H
H --> I{Success?} I -->|Yes| J[Log outcome + update routing policy] I -->|No| K[Escalate or revise spec] K --> G \u0060\u0060\u0060
Compliance and data rules you must check before routing
Treat this as a release gate, not a footnote:
- Data classification: does any prompt include PII, secrets, or customer data?
- Code/IP handling: what repos can be sent to which vendor APIs?
- Retention rules: how long are prompts, tool logs, and diffs stored?
- Audit logs: can you reconstruct who asked what and what changed?
- Access control: least privilege for agents, tools, and transcripts
For regulated teams, keep eval artifacts such as prompts, outputs, diffs, and pass/fail results, plus the decision record in an internal system of record. A low-drama way to do that is to store the routing policy, assumptions, and meeting decision log in TicNote Cloud Projects, then use Shadow AI to draft updates you can review and keep cited back to the original discussion.
Related: if you're formalizing agent work beyond coding, start with this AI agent architecture and governance playbook so routing decisions don't drift between teams.
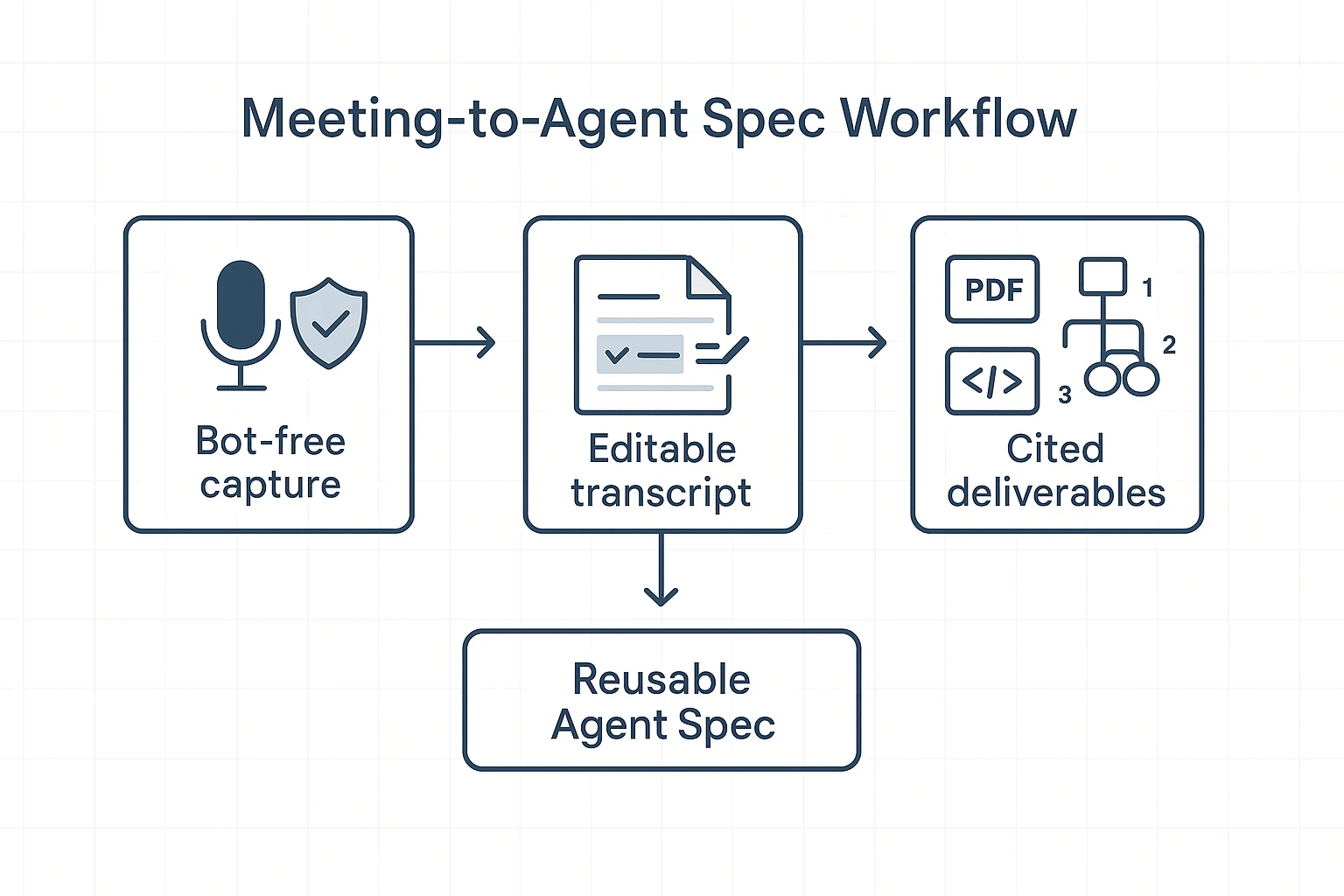
What's exclusive to TicNote Cloud for this workflow (and hard to replace)
When you're comparing Codex 5.5 vs Opus 4.7 for agentic coding, the hard part isn't the model. It's keeping eval decisions, assumptions, and meeting notes clean enough to reuse. TicNote Cloud fits this gap because it turns live discussion into editable, traceable artifacts your team can route from.
Bot-free meeting capture that keeps teams comfortable
Many engineering orgs block "meeting bots" for privacy, vendor risk, or simple meeting friction. Bot-free capture removes that debate. It also reduces the odds of "we didn't record it" when the conversation matters.
Use it for:
- Model decision meetings (trade-offs, routing rules, and fallback plans)
- Post-incident reviews (what failed, what the agent did, and what to change)
- Eval readouts (what passed, what didn't, and why)
Editable transcripts + traceable AI actions
Agent eval artifacts are only as good as the inputs. Editable transcripts let you fix names, code terms, and action items before they become the source of truth. That cuts "garbage in" that later turns into wrong routing rules.
Then, Shadow AI works inside a Project and keeps work traceable. You can verify what it generated and jump back to the supporting source text (with timestamps) instead of trusting a free-form summary.
One-click deliverables that remove copy/paste
Once the meeting is captured, you can turn talk into assets fast: an eval report, a model-routing policy, and an onboarding deck for new hires. The win is operational: fewer tabs, fewer rewrites, and fewer "where did that decision come from?" loops.
If you're building your own process, a good starting point is a shared workspace that can store model eval notes and standardize AI workspace workflows.
Conclusion: the safest way to win with Codex 5.5 vs Opus 4.7 is to standardize your agent evaluation process
There isn't a single "best" pick in the Codex 5.5 vs Opus 4.7 debate. The winner changes with your harness (tools, prompts, and guardrails) and your real workload. The metric that keeps teams honest is cost per successful completion: total spend divided by tasks that pass without human rescue.
Standardizing the process is the safest advantage. Define one eval harness, run a small task set that matches production, and measure pass rate, retries, tokens, and tool runs. Then publish a routing policy that says which model to use for which task, and when to fall back.
Treat your eval artifacts like a product. Version them, review them, and update them monthly. That's how you stop rerunning the same debates every sprint.
