

TL;DR: The top AI agent picks for recruiting (plus a safe rollout path)
Try TicNote Cloud for Free if you want an AI agent for recruiting that keeps interview notes, debriefs, and decisions searchable with clear traceability. Fast picks by scenario: high-volume + scheduling at scale (Paradox + ATS controls; add TicNote Cloud for interview/debrief capture and consistent hiring packets), hard-to-fill technical roles (SeekOut for sourcing + nurture; add TicNote Cloud for defensible debriefs), exec search (TicNote Cloud for meeting capture + decision traceability; pair a sourcing tool as needed), internal mobility (Eightfold for skills marketplace; add TicNote Cloud to document calibration and approvals).
Hiring teams lose hours to scattered notes and "who said what" debates. That slows offers and weakens audit readiness. Use TicNote Cloud to capture interviews bot-free, edit transcripts, and build project memory so every hiring packet points back to the source.
"Agentic" in hiring means the system can take multi-step actions toward a hiring goal (within limits), not just write text. It can propose, draft, and route low-risk work (like summaries and follow-ups), while humans approve high-risk steps (like outreach, reject decisions, and offers).
Non-negotiables before you roll out: approval gates for outreach, screen disposition, interview feedback, and offer steps—plus an audit trail (logs, citations back to interview notes/scorecards, and change history for prompts and rubrics).
What is an AI agent for recruiting (and how is it different from gen AI)?
Gen AI in recruiting mainly creates content. Think: drafting job posts, writing outreach emails, generating interview questions, and summarizing interview notes. An AI agent for recruiting goes a step further: it can plan and run a multi-step workflow across tools (ATS, calendar, email, sourcing platforms) to move a req forward, while following your rules.
Gen AI writes. Agents coordinate work.
Here's the clean distinction:
- Gen AI (assistive): "Write a LinkedIn message for this candidate" or "Summarize this interview."
- Recruiting agent (agentic): "Find 30 likely matches → rank by rubric → draft outreach → propose send times → create calendar holds → route for approval."
Common agent roles you'll see in TA:
- AI sourcing agent: builds lead lists and prioritizes prospects.
- AI screening agent: applies a structured rubric and flags gaps.
- AI interview scheduling automation: proposes times, sends holds, and manages reminders.
If you want a deeper breakdown of boundaries and patterns, use this agent vs assistant decision framework when you evaluate tools.
Where autonomy is real today vs where it's risky
Safe, high-ROI autonomy today is mostly "ops work":
- Scheduling, reminders, and candidate FAQs
- Cleaning up structured notes and generating interview packets
- Routing decisions for human approval (recruiter, HM, HR)
Risk climbs fast when the agent's action can harm fairness or compliance:
- Auto-rejecting candidates without review
- Unsupervised outreach at scale (brand and consent risk)
- Changing screening criteria without sign-off
- Any action that could create disparate impact
Autonomy ladder (use this in tool reviews): Assist → Recommend → Draft → Execute with approval → Execute autonomously (rare in hiring).
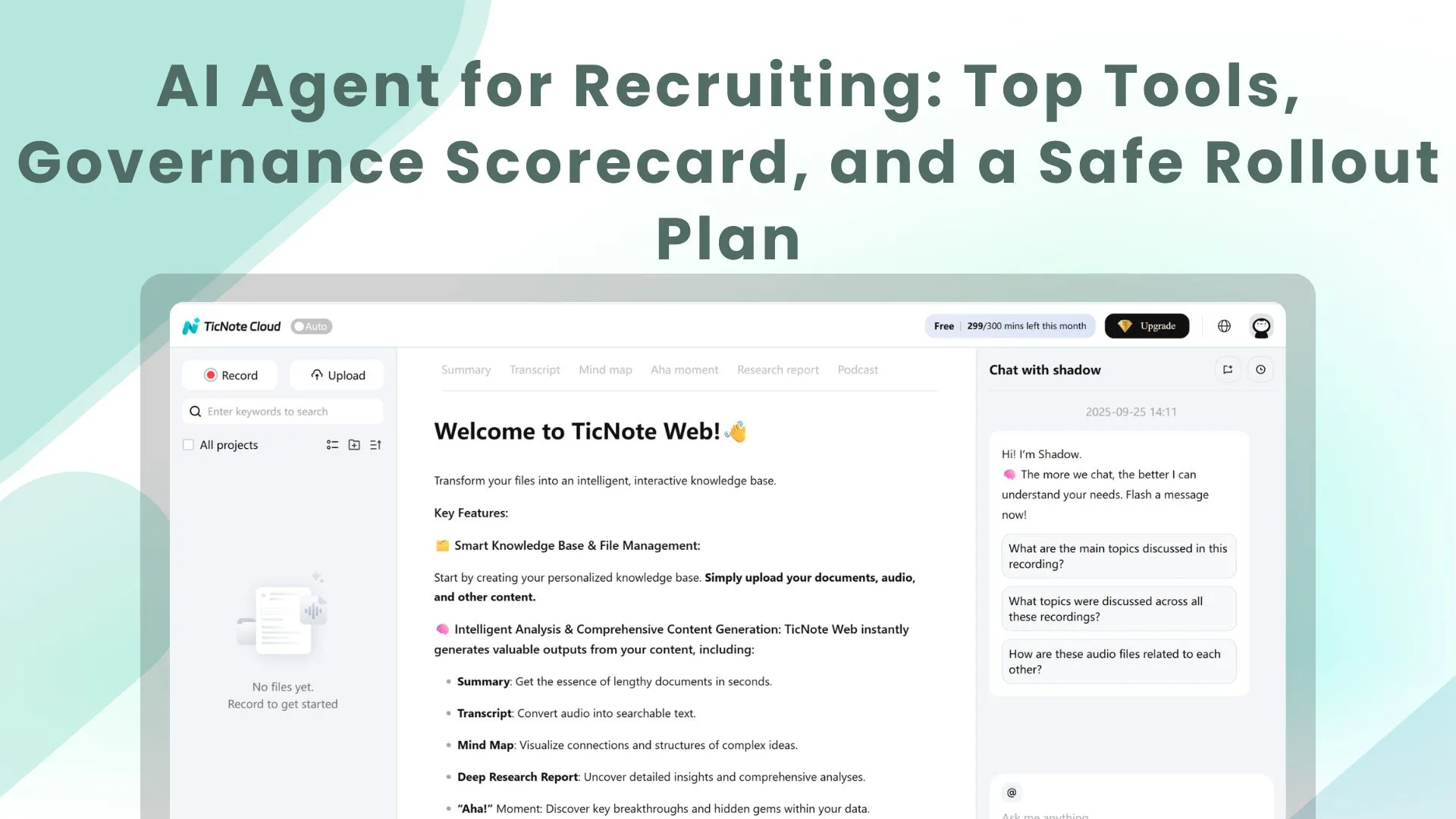
The common "agent loop" in talent acquisition
Most recruiting agents follow a loop:
- Sense: read signals from ATS stages, calendars, inbox, sourcing tools, and feedback forms.
- Decide: apply your rubric ("what good looks like"), priority rules, and governance constraints.
- Act: create tasks, draft comms, schedule interviews, prep scorecards and packets.
- Learn: accept recruiter/HM corrections within approved bounds and log what changed.
That's why this guide uses a governance-first scorecard—autonomy boundaries, audit logs, and human-in-the-loop controls—so you don't buy feature hype that you can't safely deploy.
How do AI recruiting agents change sourcing, screening, and interview ops?
An AI agent for recruiting changes the work from "do every step" to "manage the system." The agent can search, draft, route, and summarize across the full loop. But humans still own the high-risk calls: outreach, candidate disposition, and offer steps.
Sourcing + pipeline nurture (better signals, better timing)
A sourcing agent shouldn't just match keywords. It should expand the search using:
- Title patterns (step-ups, lateral moves, "bridge" roles)
- Skill adjacency (neighbor skills that predict ramp speed)
- Career trajectory (growth rate, domain switches)
- "Similar-to-top-performers" profiles (based on your own success patterns)
Then it runs a nurture loop that keeps humans in control:
- Draft 2–4 outreach variants per persona (role, seniority, location)
- Suggest send times and channels (email, LinkedIn, referrals, communities)
- Track replies and classify intent (interested, later, not a fit, wrong person)
- Shift channel mix based on response rate
- Hand off high-intent replies to a recruiter within minutes
Governance boundary: keep outreach behind a human approval gate until you've proven low risk (tone, accuracy, and compliance) on a measured sample.
Screening + rubric-based evaluation (beyond resumes)
A screening agent works best when it maps each candidate to a rubric, not a vibe. The rubric becomes your control surface.
What it should produce for each candidate:
- Must-have signals found (with evidence from resume, portfolio, or work samples)
- Missing evidence (what isn't shown yet)
- Open questions for the recruiter or hiring manager
- A plain-language "why they advanced" summary tied to rubric criteria
Non-negotiable requirement: explainability must reference job-related criteria only. No proxies for protected traits, and no "black box" ranking.
Bias control reminder: when the rubric changes, the change must be logged (who changed it, when, and why). Otherwise, you can't audit outcomes or defend decisions.
Scheduling + candidate comms (automate the easy, escalate the hard)
Scheduling agents remove the back-and-forth by automating:
- Holds and time zone conversion
- Panel coordination and interviewer load balancing
- Reschedules, cancellations, and reminders
- Calendar hygiene (avoiding conflicts and double-books)
Set clear escalation thresholds to a human, such as:
- Two failed scheduling attempts
- Any request for accommodations
- Candidate frustration or confusion
- Compensation, leveling, or offer-stage discussions
Post-interview synthesis (less ops, more signal)
After interviews, agents can turn messy notes into usable hiring artifacts: summaries, themes, risks, and next-step drafts. This is where knowledge capture matters.
With TicNote Cloud, teams can capture interviews and debriefs, edit the transcript for accuracy, and then generate scorecard drafts and decision narratives with citations back to the exact moments in the conversation. That traceability reduces "memory bias" and speeds up alignment in debrief.
If you want more examples of measurable agent workflows, see this guide on enterprise AI agent use cases and governance.
Two mini-scenarios (to set up KPI targets)
- High-volume hiring: focus on faster time-to-schedule and faster first response. A realistic near-term goal is cutting time-to-schedule by 30–50% by automating holds, reminders, and reschedules.
- Exec search: focus on decision quality and faster debrief cycles. A realistic goal is reducing debrief cycle time by 25–40% by standardizing debrief notes and producing a single decision narrative tied to evidence.
What risks and governance controls should you require before using agentic AI in hiring?
An AI agent for recruiting can move fast. That's the point. But speed without controls creates legal, fairness, and trust risk. Your governance job is simple: set clear boundaries, prove fairness with data, and keep an audit trail that stands up later.
Prevent bias with adverse impact tests (and ongoing monitoring)
Fairness risk shows up in three common ways:
- Disparate impact: one group advances at a lower rate.
- Proxy variables: "neutral" signals (school, ZIP, gaps) stand in for protected traits.
- Feedback loops: the agent learns from past hires and repeats old patterns.
Controls to require before launch:
- A pre-launch adverse impact test plan by stage (sourcing → screen → interview → offer). Use the "four-fifths rule" as a quick flag: if a group's selection rate is under 80% of the highest group, treat it as a stop-and-review signal.
- Ongoing monitoring weekly in high-volume roles and monthly in lower-volume roles. Track pass-through rates per stage, not only final hires.
- A "stop-the-line" trigger with owners and a 24–48 hour response SLA. Example triggers: sudden stage drop-off, large demographic skew, or a candidate complaint.
Documentation to require:
- Model purpose statement (what it can and can't decide).
- Data sources used (ATS fields, assessments, interview notes).
- Any rubric change log (what changed, why, who approved).
Cover compliance: notice, consent, retention, and access control
Start with a stakeholder checklist so nothing falls through cracks.
- Legal/compliance
- Map rules to workflows (EEOC/OFCCP, state laws, and global privacy).
- Draft candidate notices for AI use and data processing.
- Define retention schedules for interview notes, logs, and outputs.
- HRIS/ATS owner
- Diagram data flows (what enters the agent, what leaves, where it's stored).
- Set role-based access (recruiter vs hiring manager vs interviewer).
- Confirm deletion and legal hold processes work end-to-end.
Consent and notice basics:
- US: notice is often the practical standard, with consent expectations varying by state and tool behavior. Don't hide automation in the fine print.
- EU: you must provide clear privacy information; Regulation (EU) 2016/679 (General Data Protection Regulation), Article 12(1) requires it be given "in a concise, transparent, intelligible and easily accessible form, using clear and plain language." Build this into the apply flow and interview scheduling.
Demand auditability: event logs, evidence links, and change history
"A helpful summary" isn't a defensible hiring record. Decision traceability is.
Require these minimum logs:
- Event log: who approved what, when, and what the agent did.
- Data lineage: which resume fields, notes, and feedback were used.
- Change history: versioning for prompts, rubrics, scoring rules, and templates.
Also require citations (evidence links). Every summary claim and hiring recommendation should point back to the exact interview note, transcript segment, or structured scorecard item it came from. That's how you defend consistency across candidates.
Keep humans in the loop with hard approval gates
Set non-negotiable approval gates where the agent can draft, but not send or decide:
- Outreach messages (especially personalization and pay/benefits claims)
- Screening disposition (reject/advance)
- Interview feedback consolidation and final decision packet
- Offer and rejection communications
Add escalation rules:
- High uncertainty or missing data
- Candidate complaint or dispute
- Accommodation request
- Suspected data leak or wrong-recipient message
Error handling should be formal:
- Rollback: retract or correct messages fast.
- Quarantine: freeze the agent's actions for the job family.
- Incident review: document root cause and prevention.
Governance-first scorecard preview (use this to score vendors)
Use this rubric to compare tools on safety, not demos:
- Autonomy boundaries: can you limit actions to "draft only" per step?
- Audit logs: are actions and approvals recorded and exportable?
- Data controls: access roles, retention, deletion, and training-use policy.
- Approvals: configurable human gates and escalation paths.
If a tool can't meet these four, it's not ready for hiring.
What KPIs should you track to prove ROI from recruiting agents?
To prove ROI from recruiting agents, track a tight set of speed, cost, quality, experience, and governance KPIs. Start by baselining the last 2–4 quarters by job family and level. Then tie each metric to a specific agent action, with clear human approval gates.
KPI map: agent capability → metric → baseline → target
| Agent capability | KPI | How to measure (simple) | Baseline range | Target range |
| Sourcing outreach + follow-ups (drafts only) | Time-to-slate (days) | Requisition open → qualified slate delivered | 7–21 | 4–14 |
| Sourcing list building | Qualified leads per recruiter per week | Leads that meet must-have criteria | 15–40 | 25–60 |
| Screening assist (question sets + summaries) | Recruiter screen cycle time (mins/candidate) | Time from screen start → notes complete | 25–45 | 12–25 |
| Scheduling automation | Time-to-interview (days) | Screen pass → first interview held | 3–10 | 1–5 |
| Interview ops (agenda, packets, reminders) | Interview no-show rate (%) | No-shows ÷ scheduled interviews | 5–15% | 3–10% |
| Offer workflow nudges | Offer acceptance rate (%) | Accepted ÷ extended offers | 70–90% | +2–5 pts |
| Funnel analytics + alerts | Stage conversion (%) | Passed ÷ entered per stage | Varies | +3–8 pts at key stage |
| Governance: approval gates | % agent actions with approval | Approved actions ÷ total actions | 0–30% | 80–100% for high-risk actions |
| Governance: auditability | Audit log completeness (%) | Actions with who/when/what/why | 60–90% | 95–100% |
| Governance: fairness checks | Adverse impact monitoring cadence | Review schedule + documented results | Ad hoc/quarterly | Monthly for high-volume; per role for exec |
Baseline first, then improve the right levers
Baseline core outcomes first: time-to-fill, time-to-slate, funnel conversion, and cost-per-hire. If you only track "time saved," you'll miss where agents actually help.
Here's the clean linkage:
- Sourcing automation mostly moves time-to-slate (faster shortlist creation).
- Scheduling automation mostly moves time-to-interview (less back-and-forth).
- Screening assist moves recruiter capacity (more candidates handled per week).
- Interview ops moves debrief speed and decision quality (fewer missing notes).
Add quality and experience signals (without black-box claims)
Use pragmatic quality-of-hire proxies you can keep stable:
- 30/60/90-day hiring manager rating (simple 1–5 scale)
- Pass-through rate at each interview stage (spot false positives)
- Offer acceptance rate (proxy for fit and process quality)
For candidate experience, track:
- Median response time (in hours) to candidate questions
- Candidate NPS (or a 1–10 "how clear was the process?" score)
Guardrail: don't optimize for speed alone. Require fairness reviews and "reason codes" for major moves (reject, advance, offer).
Two scenario targets you can use
- High-volume hiring (hourly/support): cut time-to-schedule from 3–7 days to 1–3 days, and improve candidate response time from 24–48 hours to 4–12 hours.
- Exec search: cut debrief cycle time from 5–10 days to 2–5 days, and raise a "decision clarity" survey score (1–5) from ~3.0–3.5 to 4.0+.
Top AI agent tools for recruiting (comparison table + best-for picks)
Most teams don't need one "magic" AI agent. They need a controlled stack: your ATS stays the system of record, point tools handle narrow tasks, and an "agent workspace" layer captures evidence (what was said, why decisions were made, and who approved what). That's how you get speed without losing defensibility.
Start vendor-neutral: the governance-first comparison table
Use the same scorecard for every tool. Evaluate it on where it acts, what it can change, and what proof it leaves behind.
| Tool / category | Use-case fit | Autonomy boundary controls | Human-in-the-loop gates | Audit logs + citations | Data retention / permissions | Integration surfaces (ATS/HRIS, calendar/email) |
| TicNote Cloud (agent workspace) | Interview ops, knowledge capture, decision traceability | Clear scope via Projects per role/loop; keeps work tied to source meetings | Review/edit transcripts and outputs before sharing or writing back | Cited answers tied to meeting sources; traceable operations | Project permissions and private-by-default workspace | Exports + team workflows; connects to knowledge and comms tools (e.g., Slack/Notion) |
| Eightfold (enterprise suite) | End-to-end talent intelligence + early-stage automation | Ask how "auto" actions are bounded by policy | Confirm approval steps for progression/rejection | Ask for logs and decision explanations | Enterprise retention and access model | Deep ATS/HRIS ecosystem varies by deployment |
| SeekOut (Spot) | Surge hiring: sourcing + outreach with service blend | Ask what the agent can send or change by default | Require outreach and rubric approval | Require documentation of "why this prospect" and outreach history | Verify data sources, retention, and user access | Email + ATS sync depends on config |
| Paradox (conversational scheduling) | High-volume candidate comms + scheduling | Keep autonomy to scheduling and reminders | Approvals for disposition/rejection language and status changes | Logs for message history and candidate actions | Confirm candidate data handling policies | Calendar + ATS + messaging connectors |
| HireVue (assessments + intelligence) | Structured assessment workflows + analytics | Lock to validated assessments and consistent prompts | Human review for edge cases and adverse signals | Evidence trail for assessment outputs and reviewer notes | Validate retention and assessor access | ATS links for invites, results, and notes |
| Greenhouse / Lever (ATS ecosystem) | Workflow control with add-ons and rules | Use ATS rules to limit what agents can write | Require approvals before status changes | Ensure every write-back is attributable | Permission model is your primary control plane | Native integrations across HRIS, calendar, email, and apps |
A simple rule: the more a tool can change candidate status, send rejection messages, or influence selection, the tighter your approval gates should be.
Best-for picks (with "what to ask" before you buy)
TicNote Cloud — best for defensible interview ops and audit-ready knowledge capture
If you're serious about traceability, start here as your "AI agent workspace" layer. TicNote Cloud is built to capture what happened in interviews and hiring syncs, then turn it into usable assets without losing the source.
Why it fits recruiting ops:
- Bot-free recording reduces meeting friction (no extra attendee joining).
- Editable transcripts let recruiters fix names, roles, and key quotes fast.
- Projects per role or hiring loop keep notes, scorecards, and debriefs together.
- Citation-based Q&A helps you answer "Why did we decide this?" with clickable sources.
Copy-ready pricing (use as-is):
- Free ($0/month): 300 transcription mins/month; max 30 mins per web recording; import 3 documents/month; 10 AI chats/day; basic templates; live transcription, AI summarization, AI mind map, AI translation; AI aha moment (limited time free); AI podcast (limited time free); AI deep research report.
- Professional ($$12.99/month,$$79 billed annually): Everything in Free, plus 1,500 transcription mins/month; max 3 hours per web recording; import 30 documents/month; unlimited AI chat; advanced and customized templates.
- Business ($$29.99/month,$$239 billed annually): Everything in Professional, plus 6,000 transcription mins/month; max 8 hours per web recording; import 100 documents/month.
- Enterprise (contact sales): Customized usage; AI meeting agent; Single Sign-On (SSO); 7/24 customer support.
Primary evaluation questions:
- Can we restrict access by role (recruiter vs hiring manager vs legal)?
- Can outputs be traced back to the exact interview segment?
- Can we export summaries and transcripts into the ATS with consistent naming?
Eightfold (AI Interviewer) — best for enterprise suites and AI-led early stages
Eightfold fits teams that want an enterprise talent platform and automated early-stage steps. It's strongest when you treat it as a governed front door: consistent intake, early screening, and routing.
Governance questions to ask:
- What actions can run without an approval (scheduling, screening, moving stages)?
- Do we get per-candidate logs and a plain-language reason for each recommendation?
- How do we handle overrides, appeals, and exceptions?
SeekOut (Spot) — best for surge hiring with service + agentic sourcing
SeekOut is a strong fit when recruiter capacity is the bottleneck and you need pipeline fast. The key is controlling two things: the rubric (who is "qualified") and outbound messaging (what gets sent).
Governance questions to ask:
- Who approves the sourcing rubric and updates (and how often)?
- Who approves outreach before it's sent, and can we require that gate?
- Do we have a record of why each prospect matched and what was messaged?
If you're building a broader agent strategy, pair this with a workspace that preserves interview evidence and decisions; this is where a governance checklist for agent workspaces helps.
Paradox — best for candidate comms and scheduling at scale
Paradox is the "safe autonomy" pick when your biggest pain is back-and-forth scheduling and missed follow-ups. Let it run high-volume tasks like scheduling, reminders, and FAQs.
Where you should tighten control:
- Disposition and rejection messaging should require templates and approvals.
- Any status change in the ATS should be attributable and reviewable.
HireVue — best for structured assessments and analytics
HireVue fits teams that need consistent assessment steps and analytics across many roles. Treat it like a measurement tool, not a decision-maker.
What to require:
- A documented validation approach for each assessment used.
- Adverse impact monitoring expectations and who owns review.
- Clear reviewer training and consistent scoring rubrics.
Greenhouse or Lever — best for workflow control with add-ons
Your ATS should remain your control plane. Greenhouse and Lever are best when you want tight stage rules, permissions, and a clean audit trail of who moved a candidate and why.
What "good" looks like with agents:
- Agents write back only as notes, never as hidden decisions.
- Every write-back includes source context (interview ID, interviewer, timestamp).
- Stage changes require explicit human action or a named approval step.
Category fit: agentic platform vs point solution
Point solutions win when the task is narrow and low risk (scheduling, sourcing support, transcript capture). Platform suites win when you need shared data models, policy controls, and standardized workflows across regions.
A practical default stack for most teams:
- ATS (system of record) + scheduling automation + sourcing support
- Plus a meeting-to-evidence workspace for interview capture and decision traceability
Generate your first report from a meeting in minutes.
How to choose the right product
Choosing an AI agent for recruiting comes down to one question: where do you lose the most time, and where do you carry the most risk? Most enterprise teams already have an ATS (system of record). So the smart move is to add one "agent layer" to remove the biggest bottleneck, then add a knowledge and audit layer so every hiring decision stays reviewable.
Choose TicNote Cloud if you need interview knowledge, citations, and decision traceability
Pick TicNote Cloud when your pain is interview ops and decision quality. It's a strong fit if your process breaks after the interview: scattered notes, missing context, and long debriefs that turn into "who remembers what."
It fits these needs well:
- Interview note capture without bots (no tool joining the call)
- Editable transcripts so recruiters and interviewers can fix names, roles, and key details
- Project memory across the whole hiring loop (screen → panel → debrief)
- Citation-backed answers that tie summaries back to source moments for hiring packets
If you want one practical default for enterprise teams: use TicNote Cloud as the "agent workspace" to reduce meeting-note chaos and support auditability.
Choose Eightfold for enterprise TA suites and AI-led interview stages
Choose Eightfold when you're standardizing on a broad talent intelligence suite across regions and job families. It's the right pick if you want one platform to power sourcing, matching, internal mobility, and downstream TA workflows.
Governance-first checklist items to require during evaluation:
- Role-based access control (RBAC) by recruiter, hiring manager, and region
- Explainability for recommendations (what data drove the match)
- Clear retention rules for candidate data and model outputs
- Approval gates for actions (for example, before outreach or stage movement)
Choose SeekOut Spot for surge hiring with a blended service model
Choose SeekOut Spot when you have more reqs than recruiter capacity. It's a good fit if you need a sourcing + outreach engine and also want human recruiter coverage during peaks.
Guardrails that matter here:
- Approve the outreach rubric before any outreach starts
- Track and document any changes to role criteria over time
- Make sure lists, messages, and criteria changes are attributable to a person
Choose Paradox for candidate comms and scheduling at scale
Choose Paradox when scheduling is your bottleneck, especially in hourly and high-volume hiring. The win is simple: fewer back-and-forth messages and fewer dropped candidates.
Required guardrails:
- Human escalation for accommodations, sensitive topics, and edge cases
- Clear "do not answer" boundaries (medical, legal, immigration, or comp advice)
- Logs for what the assistant said, and when it handed off
Choose HireVue for structured assessments and interview analytics
Choose HireVue if you run standardized assessment programs and need consistent evaluation at scale. This is most useful when roles are repeatable and you can define what "good" looks like.
Governance note: require validation, monitoring, and clear documentation for selection procedures, so you can explain how assessments relate to job requirements.
Choose ATS ecosystems (Greenhouse/Lever) if you want workflow control with add-ons
Choose an ATS-first approach when you want the ATS to orchestrate the workflow and treat agents as assistive services. This reduces process sprawl because stages, permissions, and reporting stay anchored in one place.
Buying tip: require every agent write-back to include (1) a traceable note, (2) the author or system identity, and (3) a source link back to the underlying transcript, message, or assessment.
A simple decision rule that works in practice
Use this three-part rule to avoid tool sprawl:
- Keep one system of record (your ATS).
- Add one agent layer to fix your biggest bottleneck (sourcing, scheduling, or assessment).
- Add one knowledge/audit layer (often TicNote Cloud) so interview evidence and decisions stay easy to review.
If you want more help pressure-testing governance and security, use this AI agent security checklist for business teams before you commit.
How do you implement recruiting AI agents without breaking your process?
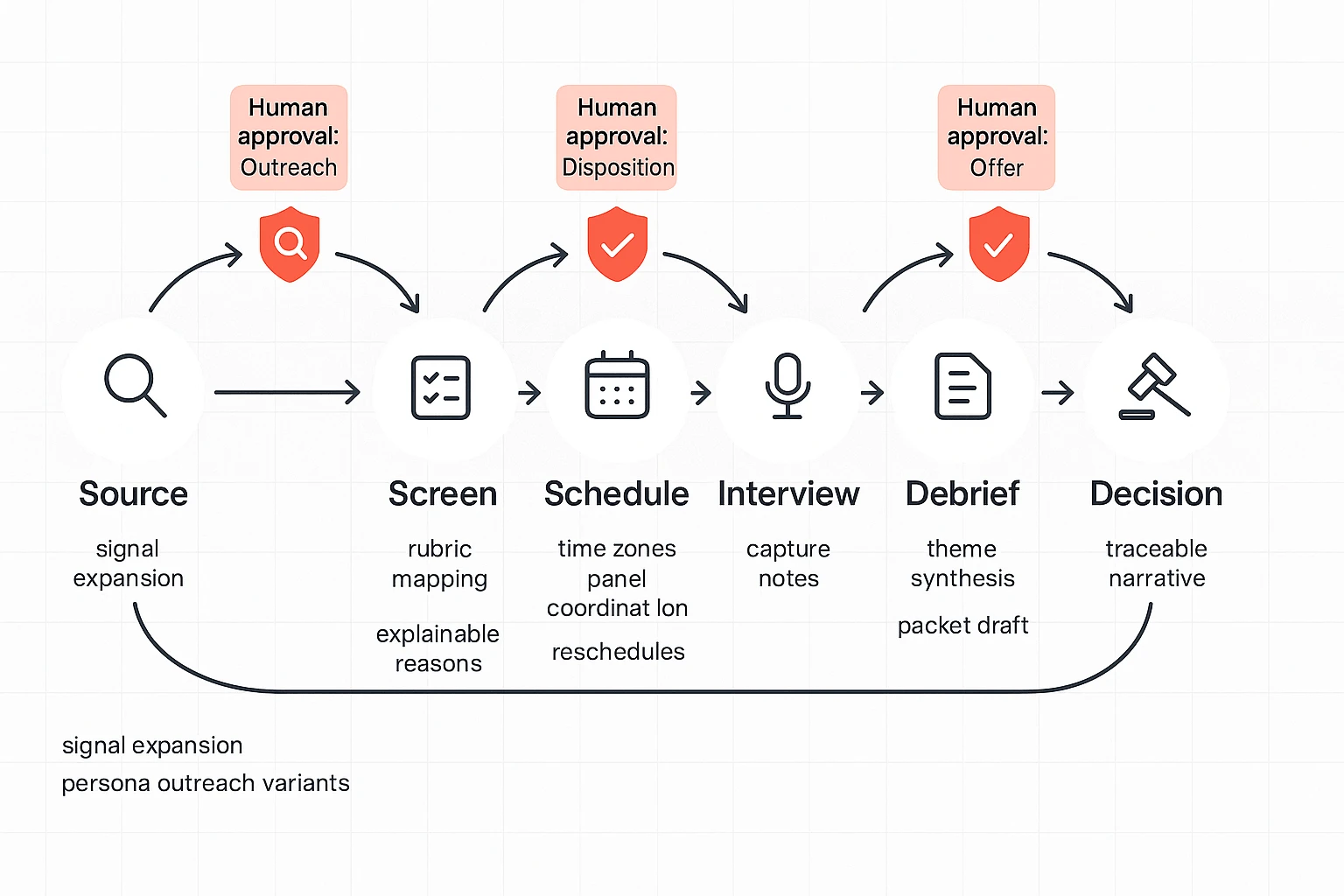
You don't "install" an agent and hope for the best. You implement it like a process change: tighten your data and rubrics first, wire it to the right systems, run a narrow pilot with approval gates, then scale with training and clear ownership. Done right, an AI agent for recruiting boosts capacity without changing who makes hiring decisions.
1) Get readiness right: data quality, rubrics, and permissions
Agents only work as well as your process inputs. Before you automate anything, standardize what the agent will read and write.
Minimum readiness checklist (hit these before a pilot):
- Clean req templates: required fields, must-have vs nice-to-have, comp band, location rules.
- Consistent ATS stages: one definition per stage, no "custom per recruiter" stages.
- Structured interview scorecards: consistent competencies, rating scale, and evidence fields.
- A shared definition of "good": examples of strong signals and disqualifiers per role family.
Permission design (keep it boring on purpose):
- Least privilege: the agent can draft and propose, not commit.
- Separation of duties: the agent can prep changes, but a human approves them.
- Named approvers: define who can approve outreach, schedule changes, and stage moves.
2) Integrate like a systems owner: ATS/HRIS, calendars, email, sourcing
Treat your ATS as the source of truth. Everything else should support it.
Integration notes to avoid messy automations:
- ATS/HRIS: read job + candidate data, then propose actions back to the ATS.
- Calendars + email: use for scheduling holds, interviewer invites, and candidate comms drafts.
- Sourcing channels: pull profiles and outreach performance, but keep messaging approvals explicit.
ATS/HRIS integration callout (don't skip this): avoid "silent writes." Require (1) a change log for every update, (2) the ability to export audit evidence, and (3) a way to see the human approver tied to each action. If you can't reconstruct who changed what and why, you can't defend the process later.
3) Run a 30/60/90-day pilot with tight scope and measurable wins
Start small so you can learn fast.
- Days 1–30 (setup + dry runs): pick one role family and one region; enable opt-in/out; run the agent in "draft-only" mode; document approval steps.
- Days 31–60 (live pilot): allow scheduling and summaries with human approval; monitor errors weekly; tune prompts and templates.
- Days 61–90 (scale decision): expand to 2–3 reqs per recruiter or one more region; formalize governance checks; lock the operating model.
Success criteria should include performance and governance:
- Capacity hours saved per recruiter/week (target: 2–6 hours).
- Time-to-slate (target: 10–25% faster).
- Candidate response time for scheduling/outreach (target: 20–40% faster).
- Approval compliance (target: 95–100% of agent actions have a recorded approver).
If you need a parallel example, borrow the same structure from this safe AI agent rollout playbook and adapt the gates to hiring.
4) Lock the operating model: RACI, training, and incident flow
If ownership is fuzzy, the pilot will drift.
RACI (simple and enforceable):
| Role | Owns what |
| Accountable: Head of TA / Recruiting Ops | Outcomes, guardrails, go/no-go decisions |
| Responsible: Recruiter lead, Ops lead | Daily use, workflow design, QA reviews |
| Consulted: Legal/Compliance, HRIS/ATS owner, DEI/People analytics | Risk review, integrations, adverse impact monitoring |
| Informed: Hiring managers | What changes, what stays the same |
Training plan (keep it practical):
- How to review outputs: check evidence, confirm stage fit, verify candidate context.
- How to correct: edit templates, fix scorecards, and log what changed.
- How to report incidents: one channel, one form, 24–48 hour triage SLA.
5) Put guardrails in writing: "can do / cannot do"
Allowed actions (agent can do these):
- Draft outreach messages and interview agendas.
- Propose slate lists with stated reasons.
- Schedule interviews after recruiter approval.
- Summarize interviews and meetings for handoffs.
Not allowed (must be human-led):
- Automated rejection decisions.
- Unsupervised outreach from a recruiter's inbox.
- Changing rubrics, scorecards, or stage definitions without approval.
- Moving candidates between stages without an audit trail and approver.
Adoption checklist (use this before you go live)
| Area | Check | Owner | Go-live gate |
| Process | Req templates standardized | Recruiting Ops | Yes |
| Process | ATS stages mapped and defined | HRIS/ATS owner | Yes |
| Quality | Scorecards structured + required evidence fields | Recruiter lead | Yes |
| Permissions | Least privilege + named approvers | Recruiting Ops | Yes |
| Integrations | ATS is system of record | HRIS/ATS owner | Yes |
| Integrations | No silent writes; exportable change logs | Legal/Compliance | Yes |
| Pilot | Scope is one role family + one region | Head of TA | Yes |
| Metrics | Baseline KPIs captured | People analytics | Yes |
| Training | Review + correction training completed | Ops lead | Yes |
| Risk | Incident reporting path tested | Legal/Compliance | Yes |
Pick one workflow to automate first (usually scheduling + interview summaries). Then measure governance from day one, not after problems show up.
Try TicNote Cloud for Free to capture interviews, keep citations, and make decisions traceable.
How to run interview knowledge capture and decision traceability (step-by-step)
Interview notes break when they're split across docs, DMs, and memory. A better system keeps every claim tied to evidence, and every edit reviewable. Below is a simple workflow using TicNote Cloud as the "workspace layer" for recruiting knowledge capture—so you can audit what was said, what changed, and why you hired.
Step 1: Create a Project and add content (one home for the whole loop)
Start by creating one Project per role (or one per hiring loop). This keeps interviews, recruiter screens, panel debriefs, and the decision memo in one place. It also makes traceability practical because everything shares one context.
In the web studio, create a Project or open an existing one. Then add your raw inputs:
- Interview recordings (audio/video)
- Interviewer notes (docs)
- Role context (job description, rubric, scorecard template, take-home prompt)
You can upload in two ways, depending on how your team works:
- Direct upload from the file area
- Upload from the Shadow AI panel (right side), then ask Shadow to file it correctly
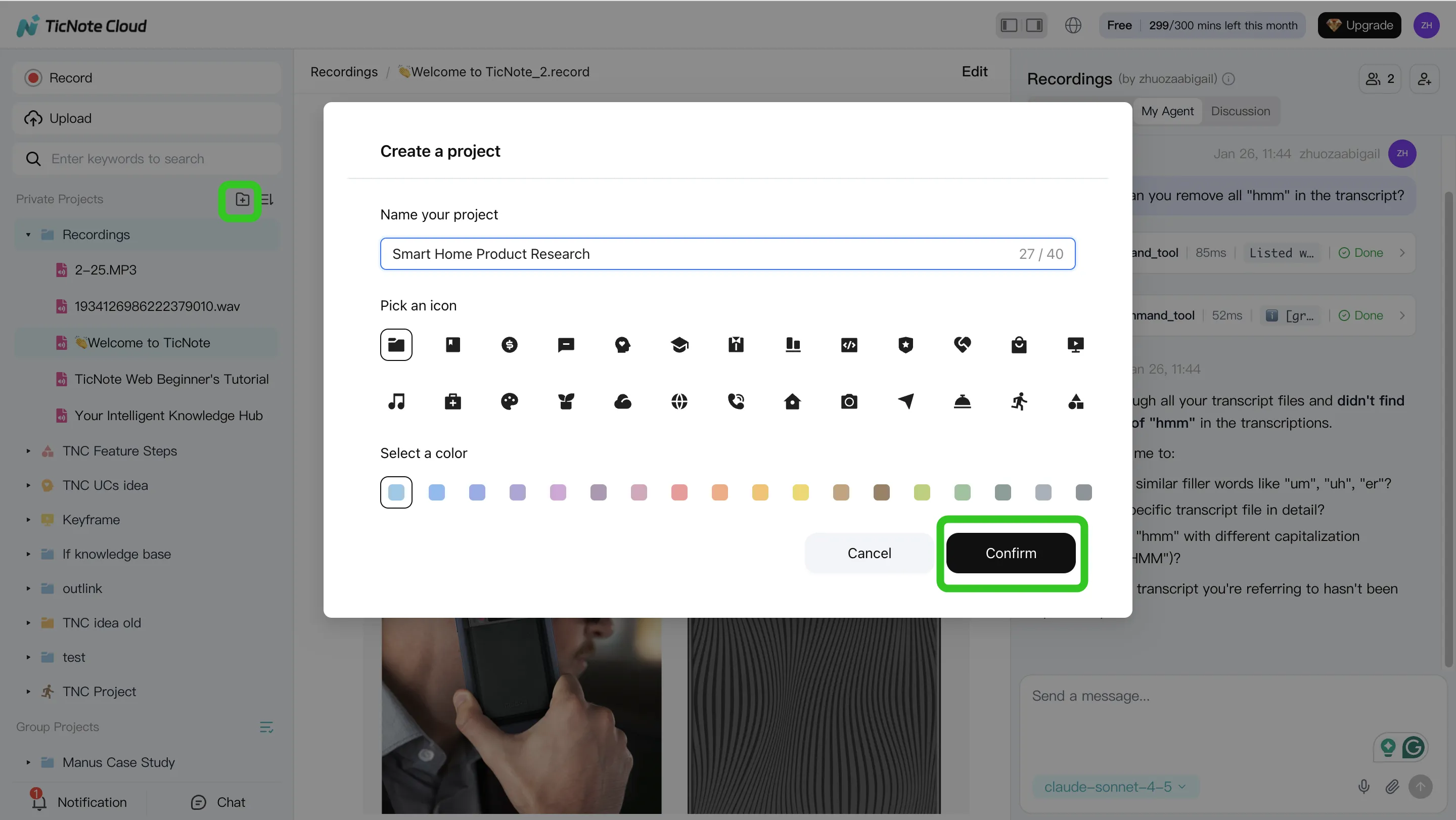
Tip: if you want clean downstream summaries, add the rubric first. That way, Shadow can map evidence to competencies from the start.
Step 2: Use Shadow AI to search, analyze, edit, and organize (with citations)
Now use Shadow AI as a Project-scoped analyst. Keep the questions narrow and hiring-specific. For decision traceability, require citations back to the exact transcript segment so reviewers can check the original wording.
Search and analysis prompts that work well for recruiting:
- "Summarize strengths and gaps against our rubric. Include citations."
- "List risks or open questions that need a follow-up interview. Include citations."
- "Compare candidate answers across three interviews by competency."
Then clean the record. Fix names, acronyms, and role terms in the editable transcript. Small edits here reduce summary errors later.
Finally, organize content into the same sections every time:
- Competency evidence
- Concerns and unknowns
- Role fit and scope match
- Follow-ups and decision inputs
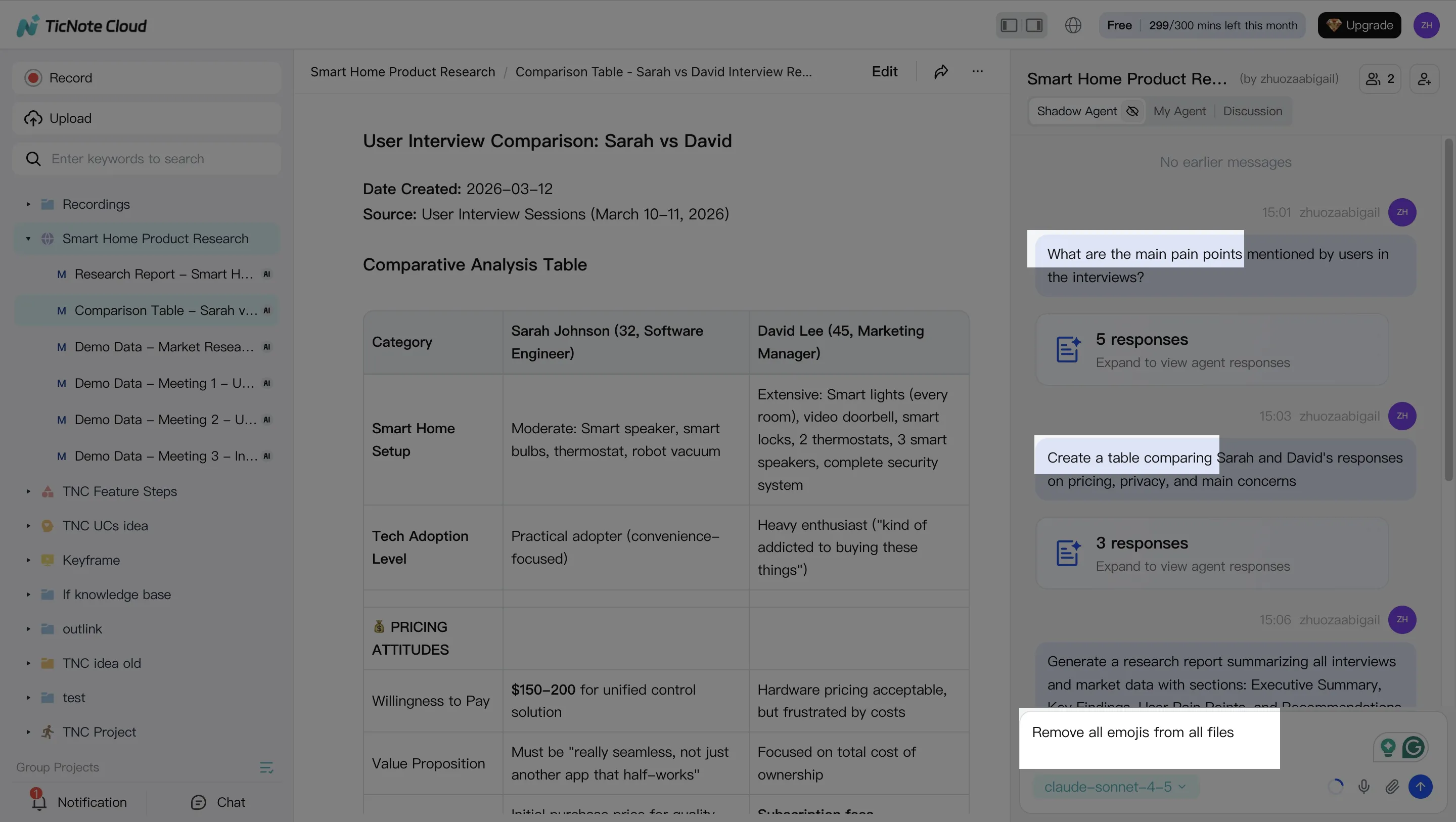
Step 3: Generate the hiring packet deliverables (so ops stays consistent)
Once your Project is organized, generate outputs that teams can review fast. You can ask Shadow directly or use the Generate button.
Common recruiting deliverables to standardize:
- Interview summary (bullets + cited evidence)
- Scorecard draft (mapped to rubric)
- Debrief agenda (what to decide, what's missing)
- Decision memo narrative (claims linked to sources)
The key is format consistency. If every role uses the same structure, calibration gets faster and less biased.
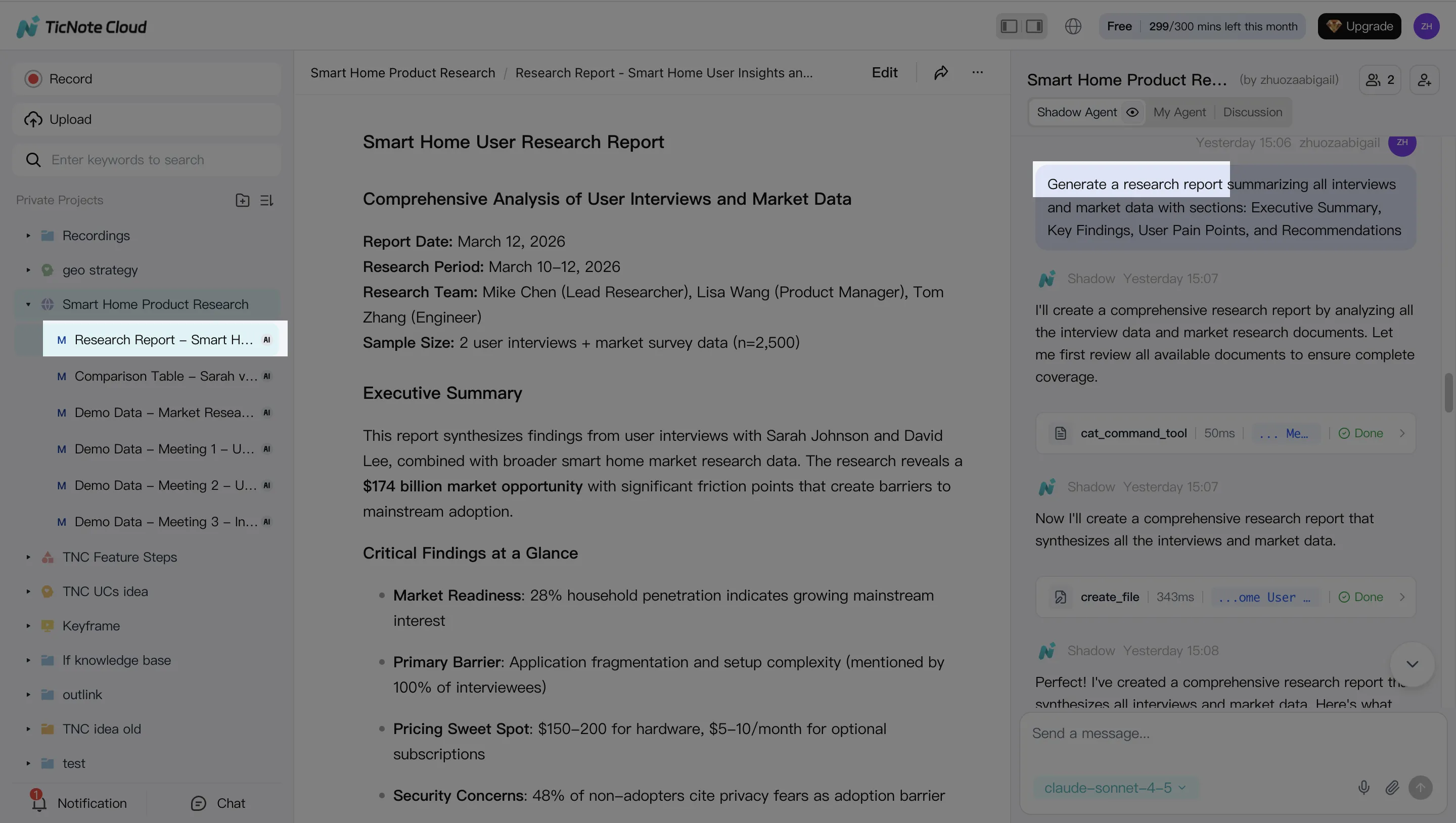
Step 4: Review, refine, and collaborate (human approval gates stay in place)
Treat Shadow's output as a draft. The team still owns the decision. In the Project, reviewers can comment, request edits, and align on final wording before anything is shared outside the panel.
Two traceability habits to make this defensible:
- Verify any important claim by clicking into the cited source segment
- Keep the "final" decision memo in the same Project as the interviews and debriefs
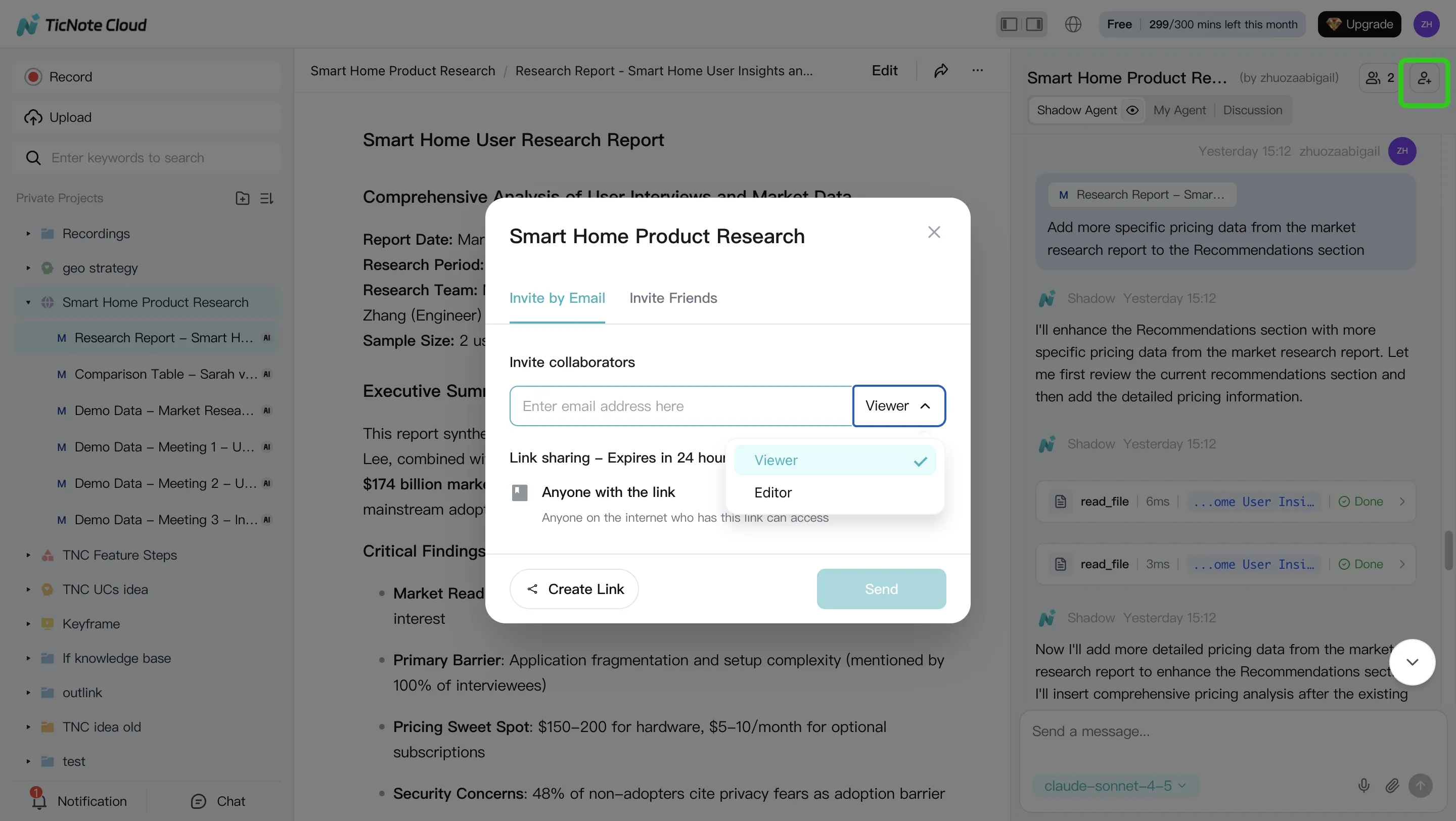
You can also share the Project with role-based access (Owner/Editor/Viewer). That keeps collaboration inside permission boundaries and makes later post-mortems easier.
Quick note: capture on the go with the mobile app
If you do quick intake calls or informal hiring-manager syncs, capture them in the app and upload them into the same Project. You'll get the same Shadow-cited answers and the same review flow, without starting a new tool chain.
Final thoughts: agentic recruiting works best with clear boundaries
Agentic AI can speed up hiring, but only if you can control it. The best AI agent for recruiting is the one you can limit, explain, and audit. That means clear rules, human approval gates, and logs you can show later.
Use a practical, defensible stack
A safe setup usually looks like this:
- ATS as the system of record for reqs, stages, and final decisions
- Point agents for clear bottlenecks like sourcing, scheduling, and assessments
- A knowledge + traceability layer to capture what happened and why (often TicNote Cloud), so interview notes, summaries, and decision threads stay linked to the source
If you can't trace a recommendation back to real interview evidence, don't automate it.
Keep humans accountable (and let agents do the busywork)
Let agents draft outreach, schedule loops, and prep interview packets. Keep judgment with recruiters and hiring teams: empathy, context, and final calls. Then pilot in one workflow, measure from day one, and expand only when the controls hold.
Try TicNote Cloud for Free and pilot interview capture with citations from day one.
